| Linux系统运行时参数命令 | 您所在的位置:网站首页 › top 查看cpu › Linux系统运行时参数命令 |
Linux系统运行时参数命令
|
目录 2 CPU性能监控 2.1 平均负载和CPU使用率 1 平均负载基础 2 使用uptime命令分析平均负载 3 平均负载与 CPU 使用率 4 CPU使用率监测命令 ps查找进程信息 top命令查询进程的cpu、内存信息 mpstat pidstat 场景一:CPU 密集型进程 场景二:I/O密集型进程 场景三:大量进程的场景 2.2 CPU上下文切换 2.2.1 什么是CPU上下文切换 2.2.2 有哪些上下文切换 2 进程上下文切换 3 线程上下文切换 4 中断上下文切换 2.2.3 怎么查看上下文切换 vmstat 2.2.4 案例分析 2.3 遇到CPU利用率高该如何排查 2.3.1 根据指标查找工具 2.3.2 根据工具查指标 C/C++Linux服务器开发/后台架构师【零声教育】-学习视频教程-腾讯课堂 2 CPU性能监控 2.1 平均负载和CPU使用率 1 平均负载基础平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。 可运行状态的进程,是指正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程。 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(UninterruptibleSleep,也称为 Disk Sleep)的进程。 平均负载其实就是平均活跃进程数。平均活跃进程数,直观上的理解就是单位时间内的活跃进程数。 2 使用uptime命令分析平均负载查看机器的启动时间、登录用户、平均负载等情况,通常用于在线上应急或者技术攻关中,确定操作系统的重启时间。 [root@ubuntusrc]# uptime 13:01:52 up 46 days, 22:03, 4 users, load average: 0.13, 0.08, 0.05 从上面的输出可以看到如下信息 当前时间: 13:01:52 系统已经运行的时间:43天22小时3分钟。 前在线用户:4个用户,是总连接数量,不是不同用户数量(开一个终端连接就算一个用户)。 系统平均负载:0.13 , 0.08, 0.05,为最近1分钟、5分钟、15分钟的系统负载情况。
比如当前平均负载为 2 时,意味着什么呢? 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU。 补充: 查看cpu信息:cat /proc/cpuinfo 直接获取cpu核数:grep 'model name' /proc/cpuinfo | wc -l
负载说明(现针对单核情况,不是单核时则乘以核数): load1:进程都堵着等待资源 注意: load < 0.7时:系统很闲,要考虑多部署一些服务 0.7 < load < 1时:系统状态不错 load == 1时:系统马上要处理不多来了,赶紧找一下原因 load > 5时:系统已经非常繁忙了 不同load值说明的问题 1)1分钟 load >5,5分钟 load 3,15分钟 load 5,5分钟 load >5,15分钟 load >5 短中长期都繁忙,系统正在拥塞 4)1分钟 load 3,15分钟 load >5 短期内空闲,中长期繁忙,不用紧张,系统拥塞正在好转 举个例子,假设我们在一个单 CPU 系统上看到平均负载为 1.73(1分钟),0.60(5分钟),7.98(15分钟),那么说明在过去 1 分钟内,系统有 73% 的超载,而在 15 分钟内,有 698% 的超载,从整体趋势来看,系统的负载在降低。 3 平均负载与 CPU 使用率 平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在使用CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如: CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的; I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高; 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。 4 CPU使用率监测命令系统自带:ps、top 第三方安装:mpstat 、pidstat 安装对应的命令:apt install stress sysstat 其中sysstat 包括了mpstat 和pidstat 。 mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有CPU 的平均指标。 pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。 压测命令:stress ,一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。 ps查找进程信息ps用一于显示系统内的所有进程。 -l或l 采用详细的格式来显示进程状况。 查看帮助:ps --help all 常用方式:ps -elf 和ps -ef
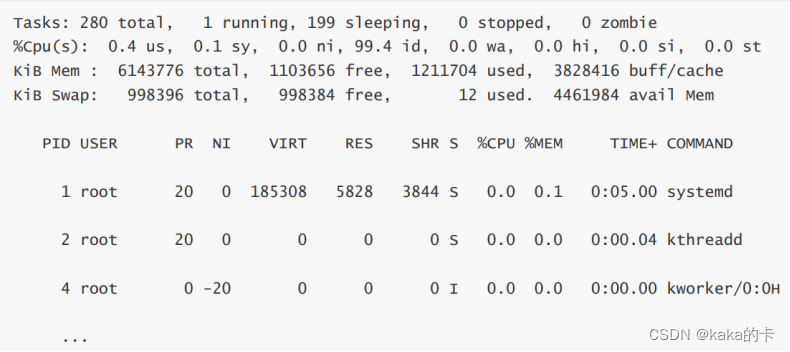
根据进程的名字或者其他信息,通过grep命令找到目标进程,也可以看到进程启动脚木的全路径。 更多参数说明: ############################################################ 常用参数: -A 显示所有进程(等价于-e)(utility) -a 显示一个终端的所有进程,除了会话引线 -N 忽略选择。 -d 显示所有进程,但省略所有的会话引线(utility) -x 显示没有控制终端的进程,同时显示各个命令的具体路径。dx不可合用。(utility) -p pid 进程使用cpu的时间 -u uid or username 选择有效的用户id或者是用户名 -g gid or groupname 显示组的所有进程。 U username 显示该用户下的所有进程,且显示各个命令的详细路径。如:ps U zhang;(utility) -f 全部列出,通常和其他选项联用。如:ps -fa or ps -fx and so on. -l 长格式(有F,wchan,C 等字段) -j 作业格式 -o 用户自定义格式。 v 以虚拟存储器格式显示 s 以信号格式显示 -m 显示所有的线程 -H 显示进程的层次(和其它的命令合用,如:ps -Ha)(utility) e 命令之后显示环境(如:ps -d e; ps -a e)(utility) h 不显示第一行 ===================================ps 的参数说明============================= l 长格式输出; u 按用户名和启动时间的顺序来显示进程; j 用任务格式来显示进程; f 用树形格式来显示进程; a 显示所有用户的所有进程(包括其它用户)。显示所有进程 -a 显示同一终端下的所有程序 x 显示无控制终端的进程; r 显示运行中的进程; ww 避免详细参数被截断; -A 列出所有的进程 -w 显示加宽可以显示较多的资讯 -au 显示较详细的资讯 -aux 显示所有包含其他使用者的进程 -e 显示所有进程,环境变量 -f 全格式 -h 不显示标题 -l 长格式 -w 宽输出 a 显示终端上地所有进程,包括其他用户地进程 r 只显示正在运行地进程 x 显示没有控制终端地进程 常用的选项是组合是 aux 或 lax,还有参数 f 的应用。 pids 只列出进程标识符,之间运用逗号分隔, 该进程列表必须在命令行参数地最后一个选项后面紧接着给出, 中间不能插入空格。比如:ps -f1,4,5 显示的是进程ID为1,4,5的进程 下面介绍长命令行选项,这些选项都运用“--”开头: --sort X[+|-] key [,[+|-] key [,…]] 从SORT KEYS段中选一个多字母键.“+”字符是可选地, 因为默认地方向就是按数字升序或者词典顺序,“-”字符是逆序排序(即降序). 比如: ps -jax -sort=uid,-ppid,+pid. --help 显示帮助信息. --version 显示该命令地版本信息. 在前面地选项说明中提到了排序键,接下来对排序键作进一步说明. 需要注意的是排序中运用的值是ps运用地内部值,并非仅用于某些输出格式地伪值. 排序键列表见下表. ============排序键列表========================== c cmd 可执行地简单名称 C cmdline 完整命令行 f flags 长模式标志 g pgrp 进程地组ID G tpgid 控制tty进程组ID j cutime 累计用户时间 J cstime 累计系统时间 k utime 用户时间 K stime 系统时间 m min_flt 次要页错误地数量 M maj_flt 重点页错误地数量 n cmin_flt 累计次要页错误 N cmaj_flt 累计重点页错误 o session 对话ID p pid 进程ID P ppid 父进程ID r rss 驻留大小 R resident 驻留页 s size 内存大小(千字节) S share 共享页地数量 t tty tty次要设备号 T start_time 进程启动地时间 U uid UID u user 用户名 v vsize 总地虚拟内存数量(字节) y priority 内核调度优先级练习: (1)检测是否有活动进程: sudo ps -ef |grep "nginx: master process" |grep -v grep (2)检测有几个同样的活动进程 sudo ps -ef |grep "nginx: master process" |grep -v grep |wc -l top命令查询进程的cpu、内存信息top命令用于查看活动进程的CPU和内存信息,能够实时显示系统中各个进程的资源占用情况,可以按照CPU、内存的使用情况和执行时间对进程进行排序。 使用方式:top
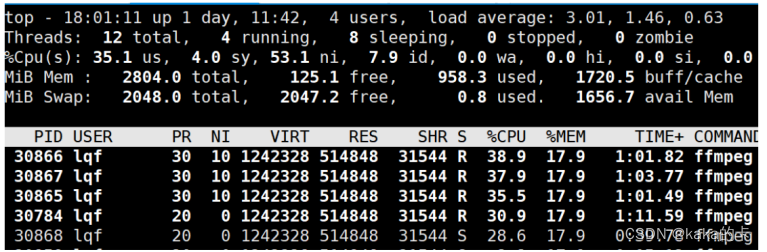
从输出可以看到整体的CPU占用率、CPU负载,以及进程占用CPU和内存等资源的情况。 我们可以用以下所示的top命令的快捷键对输出的显示信息进行转换。 t:切换报示进程和CPU状态信息。 n:切换显示内存信息。 r:重新设置一个进程的优先级。系统提示用户输人需要改变的进程PID及需要设置的进程优先级,然后输入个正数值使优先级降低,反之则可以使该进程拥有更高的优先级,即是在原有基础上进行相加,默认优先级的值是100 k:终止一个进程,系统将提示用户输入需要终止的进程PID o s:改变刷新的时间间隔。 u:查看指定用户的进程。 练习: top 命令查找cpu占用率最高的程序,找到对应的PID top -Hp pid ,查看具体进程下的线程,比如
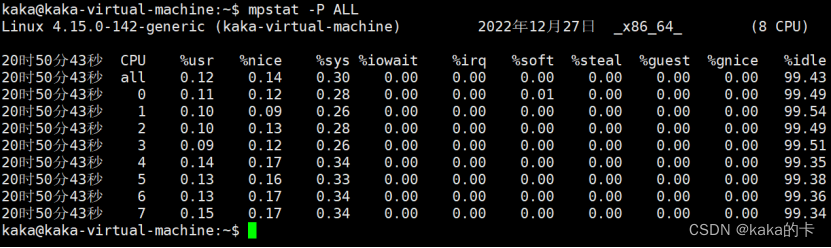
此命令用于实时监控系统CPU的一些统计信息,这些信息存放在/proc/stat文件中,在多核CPU系统里,不但能查看所有CPU的平均使用信息,还能查看某个特定CPU的信息。 使用方式:mpstat [-P {cpu|ALL}] [internal [count]] 当mpstat不带参数时,输出为从系统启动以来的平均值
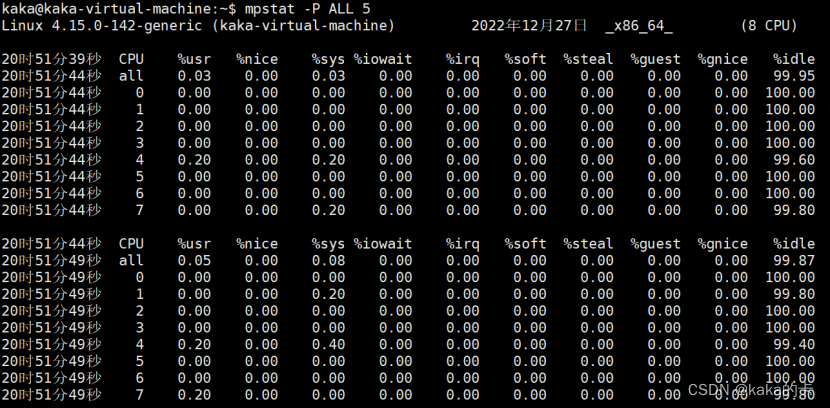
我们可以看到每个CPU核心的占用率、I/O等待、软中断、硬中断等。 输出各参数含义: 参数 含义 -P {cpu l ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值 internal 相邻的两次采样的间隔时间 count 采样的次数,count只能和internal一起使用 使用mpstat -P ALL 5 2命令,表示每5秒产生一个报告,总共产生2个。
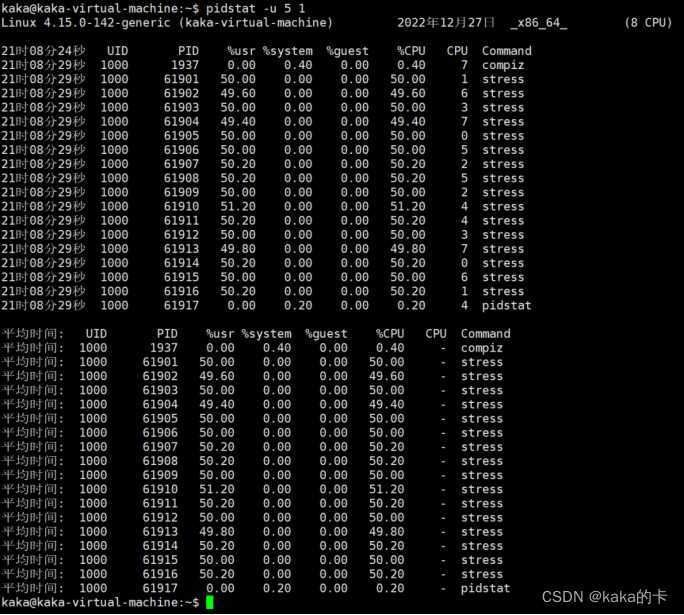
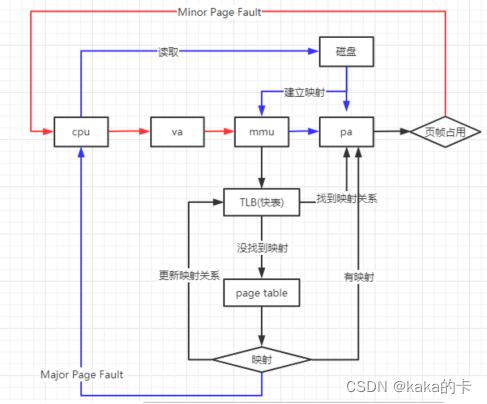
输出参数含义 当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。 输出各参数含义: 参数 释义 从/proc/stat获得 数据 CPU 处理器ID %usr 在internal时间段里,用户态的CPU时间(%),不包含 nice 值为负进程 usr/total*100 %nice 在internal时间段里,nice值为负进程的CPU时间(%) nice/total*100 %sys 在internal时间段里,核心时间(%) system/total*100 %iowait 在internal时间段里,硬盘IO等待时间(%) iowait/total*100 %irq 在internal时间段里,硬中断时间(%) irq/total*100 %soft 在internal时间段里,软中断时间(%) softirq/total*100 %steal 显示虚拟机管理器在服务另一个虚拟处理器时虚拟CPU处在非 自愿等待下花费时间的百分比 steal/total*100 %guest 显示运行虚拟处理器时CPU花费时间的百分比 guest/total*100 %gnice gnice/total*100 %idle 在internal时间段里,CPU除去等待磁盘IO操作外的因为任何 原因而空闲的时间闲置时间(%) idle/total*100 pidstatpidstat用于监控全部或指定的进程占用系统资源的情况,包括CPU、内存、磁盘I/O、程切换、线程数等数据。 -u:表示查看cpu相关的性能指标 -w:表示查看上下文切换情况,要想查看每个进程的详细情况,要加上-w -t:查看线程相关的信息,默认是进程的;常与-w结合使用(cpu的上下文切换包括进程的切换、线程的切换、中断的切换) -d:展示磁盘 I/O 统计数据 -p:指明进程号 使用方式:pidstat [option] interval [count] 使用范例:pidstat -urd -p 进程ID [root@VM_0_ubuntu ~]# pidstat -urd -p 24615 Linux 3.10.0-957.5.1.el7.x86_64 (VM_0_ubuntu) 08/22/2019 x86_64 (1 CPU) 输出CPU的使用信息 -u 03:48:12 PM UID PID %usr %system %guest %CPU CPU Command 03:48:12 PM 0 24615 0.00 0.00 0.00 0.00 0 nginx 输出内存的使用信息 -r 03:48:12 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command 03:48:12 PM 0 24615 0.00 0.00 58252 24940 1.32 nginx 输出磁盘I/O的使用信息 -d 03:48:12 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command 03:48:12 PM 0 24615 0.07 0.00 0.00 nginx 03:20:54 PM UID PID cswch/s nvcswch/s Command 03:20:54 PM 0 24615 0.03 0.00 nginx CPU信息 %usr #用户层任务正在使用的CPU百分比(with or without nice priority ,NOT include time spent running a virtual processor) %system #系统层正在执行的任务的CPU使用百分比 %guest #运行虚拟机的CPU占用百分比 %CPU #所有的使用的CPU的时间百分比 CPU #处理器数量 Command #命令 内存信息 PID #进程号 minflt/s #每秒次缺页错误次数(minor page faults),次缺页错误次数意即虚拟内存地 址映射成物理内存地址产生的page fault次数 majflt/s #每秒主缺页错误次数(major page faults),当虚拟内存地址映射成物理内存地址时,相应的page在swap中,这样的page fault为major page fault,一般在内存使用紧张时产生 VSZ #该进程使用的虚拟内存(以kB为单位) RSS #该进程使用的物理内存(以kB为单位) %MEM #当前任务使用的有效内存的百分比 Command #任务的命令名 磁盘I/O PID #进程号 kB_rd/s #每秒此进程从磁盘读取的千字节数 kB_wr/s #此进程已经或者将要写入磁盘的每秒千字节数 kB_ccwr/s #由任务取消的写入磁盘的千字节数 Command #命令的名字 上下文切换 PID #PID号 cswch/s #每秒自动上下文切换 nvcswch/s #每秒非自愿的上下文切换 Command #命令 场景一:CPU 密集型进程 1.模拟一个 CPU 使用率 100% 的场景 stress --cpu 1 --timeout 600 2.在第二个终端运行 uptime 查看平均负载的变化情况
3. 第三个终端运行 mpstat 查看 CPU 使用率的变化情况
正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。 4. 查看是哪个进程导致了cpu使用率为100%
1.第一个终端运行 stress命令模拟I/O压力 stress -i 1 --timeout 600 2.第二个终端运行 uptime 查看平均负载的变化情况 Uptime 3.第三个终端运行mpstat查看CPU使用率的变化情况 mpstat -P ALL 5 1 4.查看是哪个进程,导致iowait较高 pidstat -u 5 1 场景三:大量进程的场景 1.第一个终端模拟16个进程 stress -c 16 --timeout 600 2.第二个终端uptime Uptime 3.使用pidstat查看进程情况 可以看出,16 个进程在争抢 8 个 CPU,这些超出 CPU 计算能力的进程,最终导致 CPU 过载。 2.2 CPU上下文切换 2.2.1 什么是CPU上下文切换所谓的上下文切换,就是把上一个任务的寄存器和计数器保存起来,然后加载新任务的寄存器和计数器,最后跳转到新任务的位置开始执行新任务。 根据任务的不同,CPU 的上下文切换就可以分为几个不同的场景,也就是进程上下文切换、线程上下文切换以及中断上下文切换。 2.2.2 有哪些上下文切换1 系统调用上下文切换 linux 进程既可以在用户空间运行,又可以在内核空间中运行。 当它在用户空间运行时,被称为进程的用户态;当它进入进入内核空间的时候,被称为进程的内核态从用户态到内核态的转变过程,需要通过系统调用来完成 CPU 寄存器里原来的指令位置是在用户态。但是为了执行内核态代码,需要先把用户态的位置保存起来,然后寄存器更新为内核态指令的新位置。最后跳转到内核态运行内核任务。 当系统调用结束后,CPU 寄存器需要恢复原来保存的用户态位置,然后再切换到用户空间,继续运行进程。一次系统调用发生了两次 CPU 上下文切换! 系统调用过程中对用户态的资源没有任何影响,也不会切换进程,所以也称为特权模式切换. 应用层(用户态)send, 真正发送数据 内核态 recv 2 进程上下文切换进程是由内核来管理和调度的,所以进程的切换只发生在内核态。进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。 进程的上下文切换在保存当前进程的内核状态和 CPU 寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后再刷新进程的虚拟内存映射关系和用户栈,刷新虚拟内存映射就涉及到 TLB 快表 (虚拟地址缓存),因此会影响内存的访问速度。
单次进程上下文切换的 CPU 时间在几十纳秒到数微秒之间。特别是在进程上下文切换次数较多的情况下,很容易导致 CPU 将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而影响cpu 的实际使用率。 进程上下文切换的原因 其一,为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。(被动切换) 其二,进程在系统资源不足,这个时候进程也会被挂起,并由系统调度其他进程运行。(主动切换) 其三,当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。 其四,当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。 第五发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。 3 线程上下文切换线程与进程的区别在于:线程是调度的基本单位,而进程是资源分配基本单位。内核中的任务调度,实际调度的是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。 1:当进程只有一个线程时,可以认为进程就等于线程 2:当进程拥有多个线程时,共享虚拟内存和全局变量等资源。这些资源在上下文切换时不需要修改 3:线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时需要保存 线程的上下文切换分为两种 1.前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样。 2.前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据 4 中断上下文切换为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。 跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。中断上下文只包括内核态中断服务程序执行所必需的状态,包括 CPU 寄存器、内核堆栈、硬件中断参数等 2.2.3 怎么查看上下文切换过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成了系统性能大幅下降的一个元凶。 可以使用 vmstat 这个工具,来查询系统的上下文切换情况。此命令显示关于内核线程、虚拟内存、磁盘I/O 、陷阱和CPU占用率的统计信息。 vmstatvmstat [options] [delay [count]] # 每隔5秒输出1组数据
需要注意如下内容。 r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程数。 b(Blocked)则是处于不可中断睡眠状态的进程数。 buff:是I/O系统存储的磁盘块文件的元数据的统计信息。 cache:是操作系统用来缓存磁盘数据的缓冲区,操作系统会自动一调节这个参数,在内存紧张时操作系统会减少cache的占用空间来保证其他进程可用。 si和so较大时,说明系统频繁使用交换区,应该查看操作系统的内存是否够用。 bi和bo代表I/O活动,根据其大小可以知道磁盘I/O的负载情况。 in(interrupt)则是每秒中断的次数。 cs:参数表示线程环境的切换次数,此数据太大时表明线程的同步机制有问题。 2.2.4 案例分析上下文切换频率是多少次才是正常的? 使用sysbench 来模拟系统多线程调度切换的情况。 有命令,都默认以 root 用户运行,运行 sudo su root 命令切换到 root 用户。 1.测试工具sysbench的安装: apt install sysbench 2.使用vmstat查看空闲系统的上下文切换次数 // 间隔1秒后输出1组数据
3.在另一个终端开始压测 // 以10个线程运行5分钟的基准测试,模拟多线程切换的问题 sysbench --num-threads=10 --max-time=300 --max-requests=10000000 --test=threads run 4.使用vmstat查看
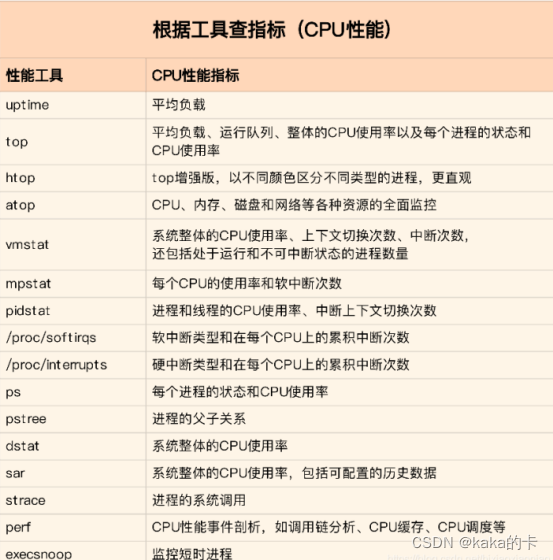
cs 列:的上下文切换次数从之前的 35 骤然上升到了 139 万。 r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU 的个数 2,所以肯定会有大量的 CPU 竞争。 us(user)和 sy(system)列:这两列的 CPU 使用率加起来上升到了 100%,其中系统 CPU 使用率,也就是 sy 列高达 84%,说明 CPU 主要是被内核占用了。 in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题。 综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待 CPU 的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统 CPU 的占用率升高。 2.3 遇到CPU利用率高该如何排查遇到CPU使用率高时,首先确认CPU是消耗在哪一块,如果是内核态占用CPU较高: 1. %iowait 高,这时要重点关注磁盘IO的相关操作,是否存在不合理的写日志操作,数据库操作等; 2. %soft或%cs 高,观察CPU负载是否较高、网卡流量是否较大,可不可以精简数据、代码在是否在多线程操作上存在不合适的中断操作等; 3. %steal 高,这种情况一般发生在虚拟机上,这时要查看宿主机是否资源超限; 如果是用户态较高,且没有达到预期的性能,说明应用程序需要优化。 2.3.1 根据指标查找工具
|









【本文地址】